
どうも!こんにちは、遠藤です。
『第6回 データリテラシー勉強会』を開催しました🖋👩🏫
今回は、『統計学』というテーマでした。
これまで、データを読み解いたり、作成について講義してきましたが、そのデータを元に意思決定をしていくためには『統計』から判断しなければならないです。
一部ではありますが、勉強会の様子をご紹介します!
講師紹介
講師の方は、ITベンチャーの人事をはじめ、データサイエンスに関する講師業などもされている方をお招きました。
統計学やデータ活用の研修に累計200回以上登壇、2021年春にAI・EXPOで100名規模のセミナーに登壇、日経XTECHでデータ分析に関する記事の執筆などの実績がある方です。

勉強会の内容
講義内容としては、
①統計学とは?
②確率について
③仮説検定
④実践(ワーク)
で約90分の勉強会となりました!
勉強会をチラ見せ
一部、内容を公開しますと・・・
統計学とは、『手元にある限られたデータを元に、客観的無根拠に基づいて、あらゆる事象や、全体像の特徴を掴むこと』です。
簡単にいうと、自分の固定概念を排除して、客観的にデータを見て、どんな特徴があるのかを判断することが統計という分野です。
身近な代表例だと、『ABテスト』が挙げられます。
たとえば、『Aでは2.3%』『Bでは1.0%』という検証結果だった場合、差分は『1.3%』ですが、Aの方が間違いなく良い結果だと判断できるかどうかは統計に基づいた判断をしなければいけないです。

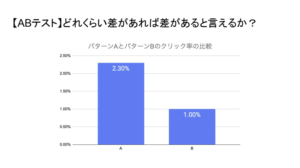
こうした検証結果から、どちらが最適解なのかを判断・意思決定をしていくにあたっては、『仮説検定』を用いることで、決めることができます。
仮説検定の手順は、以下の通りです。
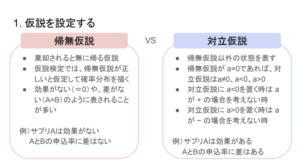
1. 仮説を設定する
2. 有意水準の決定(通常5%)
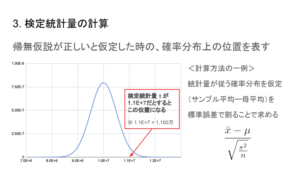
3. 検定統計量の計算
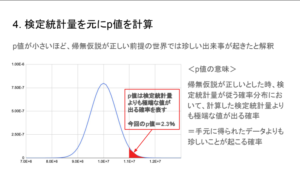
4. 検定統計量を元にp値を計算
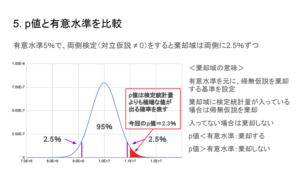
5. p値と有意水準を比較
p値<有意水準:帰無仮説を棄却できる
p値>有意水準:帰無仮説を棄却できない
簡単にいうと、有意水準を5%で設定し、5%を下回るか、上回るかで、検証効果があったどうかを判断することができます。


以上です!
今回の内容は、大学で10講義分にあたる内容を、さらに圧縮した内容だったので、難しいところもありましたが、データを読み書きできるようになり、定量的なデータから意思決定ができるスキルをインプットできた機会でした。
本講義内容はアーカイブに残しておりますが、次回参加される方のみに配信します。
次回の開催アナウンスもお見逃しなく♪
参加者の感想

無料エンジニアコミュニティ
すでに430名以上が参加中のコミュニティの詳細はこちら。
